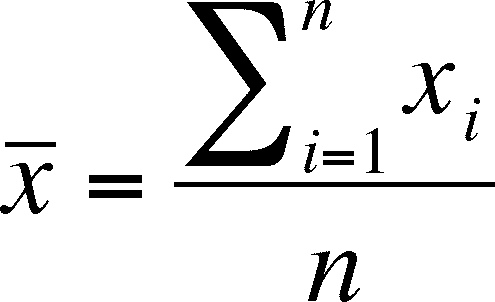|
BIOL 3110
Biostatistics Phil Ganter 302 Harned Hall 963-5782 |
| Russulaceae, probably in the genus Lactaria |
|
|
BIOL 3110
Biostatistics Phil Ganter 302 Harned Hall 963-5782 |
| Russulaceae, probably in the genus Lactaria |
|
Introduction & Descriptive Statistics
Back to:
Academic
Page |
Tennessee
State Home page |
Bio
311 Page |
Ganter
home page |
Unit Organization:
This unit is composed of many definitions as we go through some basic components of statistics: the means of summarizing data (=descriptive statistics)
Below are bookmarks to the several sections
Frequency Tables and Distributions
Problems:
Problems for homework
- 2.4, 2.10, 2.15, 2.20, 2.25, 2.28, 2.41, 2.47 (in addition, use the same data and calculate the mean, s. d. and C. V.)
Suggested Problems
- 2.66, 2.68, 2.69, 2.73, 2.77 (the top three distributions, labelled I, II, and III, belong to question 2.26, which is a good one if you want the challange, but ignore them for question 2.77)
Link to temporary page with the homework problems
A variable is anything that can have different values or qualities
Categorical
Ordinal (ordered categories, like life history stages for insects - egg, larval instar #1, etc.)
Non-ordinal (unordered, like the sexes)
Quantitative
Discrete (things that are counted, like population size)
Continuous (things that are measured, like height)
Frequency Tables and Distributions
A means of compacting the data and an aid to understanding some of the statistical properties of a collection of data.
Curve shapes
Bimodal (or tri-, etc.), Unimodal
Normal (bell curve)
Leptokurtic vs. Platykurtic - sharp vs. flat, platykurtic might mean a two modes close by (perhaps two sets of data have been combined)
Skewed vs. Symmetric
Exponential (decay) -- negative monotonic
Histograms -- utility in data presentation, visual impact
Categorical data -- columns are not touching (columns should touch for continuous data)
Grouping of Continuous Data
Determination of group sizes
Area under curve = proportional contribution of category to total
Proportional Histograms (Relative Frequency in book) -- making histograms comparable
Stem and Leaf plots
Summation Notation and Statistical Inference
Statistical Inference
a measurement or an observation is a value for a variable taken from an observed individual
a sample is the set of measurements or observations taken from the total Population
The Population is the larger group about which you wish to draw some sort of conclusion
You use statistics done from the sample to draw an inference about the population (it is inferred because you are guessing from the particular to the general)
sample descriptive statistics are denoted by the usual English letters, but the population statistic by Greek letters (mean =
, standard deviatio=
)
sample mean =
, but population mean is
estimated values are sometimes symbolized by placing a caret rather than a bar over them
Summation Notation
is read as "the sum of the observations from the first one to the nth one"
i is the INDEX, which labels all of the sample observations from 1 to the total sample size (so that each observation has its own index number)
X is the variable.
n is the total number of values (= the sample size)
Mean
because the mean can be biased when there are unusually large or small observations in a sample, it is possible to decide to Trim the mean (drop the bottom and top 5 or 10 % of the observations)
this must be done before the data is inspected on the basis that one can not throw out data just because it is "too big"
Median
Mode (not in book, but an acceptable measure of central tendency in some cases)
Range
most conservative, makes no assumptions, not estimated but not useful for statistical interpretation
Quartiles
divide the observations into quarters, (the median would also be the division between the second and third quartiles)
Interquartile Range
distance between beginning of second quartile and end of third (so 50% of all data points lie between)
Standard Deviation
n = sample size, n-1 is a correction for the degree to which the sample varied (called the degrees of freedom)
The book points out that when there is only one observation, dividing by n would give you a value of 0 for s, which is misleading because you have no information to base this on (given that you have only one measurement), but if you divide by n-1, the value is undefined (division by zero), which is consistent with the situation
Normal Curve percentages -
68% are ± 1 s. d., 95% are ± 2 s. d., 99% are ± 3 s. d.
Chebyshev's Rule - for any distribution - 75% are ± 1 s. d., 89% are ± 2 s. d.
Computational Formula
Variance
the square of the standard deviation (written
)
notice that the measurement units are also squared, so that you never report mean ± variance (as it makes no sense)
uses of variance -- it is used in some statistical tests
Coefficient of Variation
C. V. is just the ratio of the s. d. to the mean, usually expressed as a percentage
X' is the symbol for transformed data
Linear
usually to change a scale (multiplicative), or to add or subtract a common factor
all are "natural", so that you can perform the dame procedure on the mean to change it to the transformed value
all change the mean, but additive or subtractive do not change s. d. (s. d. multiplicative change is also natural)
Nonlinear
must recalculate means and s. d. for nonlinearly transformed data
Taking the logarithm (natural or base 10)
Taking the square root of the value
Last updated August 20, 2006