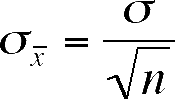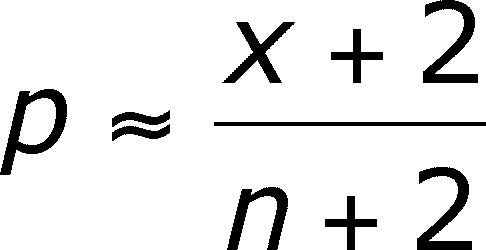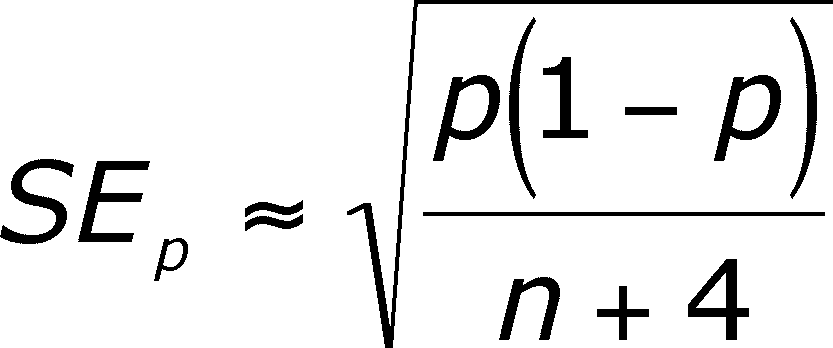|
|
BIOL 3110
Biostatistics Phil Ganter 320 Harned Hall 963-5782 |
|
|
BIOL 3110
Biostatistics Phil Ganter 320 Harned Hall 963-5782 |
Confidence Intervals
Back to:
Academic
Page |
Tennessee
State Home page |
Bio
311 Page |
Ganter
home page |
Unit Organization:
Problems:
Problems for homework (assume a 6. in front of each)
- 3, 7, 10, 25, 29, 32, 34, 36, 52, 58
Suggested Problems (assume a 6. in front of each)
- 1, 2, 12, 14, 16, 18, 27, 31, 39, 43, any from the last section of problems
This is the reason for doing statistics in the first place.
Statistical estimation has two components
In this lecture, we will learn how to construct confidence intervals, which depend on us knowing two things:
As discussed before, the best estimate of the true mean is a sample mean (or, better, a mean of sample means)
this leaves us with the problem of estimating the true standard deviation (it's not exactly s)
First, let's recall what the standard deviation is:
The standard deviation of the sample is related to but not equal to the standard deviation of the population.
The standard deviation of the sample is larger because a sample is an estimate and, to be conservative about what we think we know, we divide by n-1 rather than n.
The standard deviation of means of samples drawn from a population is likely to be smaller than the standard deviation estimated from a single sample or even smaller than the true population standard deviation
When means are calculated from samples drawn randomly from a population, they will most often be closer to the true mean than will a single data point drawn from the population at random
Thus, a standard deviation calculated from 10 means will be smaller than a standard deviation calculated from 10 values drawn at random from the population
To
calculate the standard error of means, we need a formulation that will guarantee
that it is smaller than the population standard deviation (![]() )
)
There is a second consideration and that is that samples are not all equally good
Means calculated from large samples are more likely to be nearer the true mean (
) than those calculated from small samples.
If this is so, then a standard deviation calculated from small sample means (which are clustered less tightly about the true mean) should be larger than a standard deviation calculated from large means (which are clustered more tightly about the true mean)
So, taking both considerations into effect, we use this equation:
Note that we use the square root of the sample size (remember that
is a square root also)
A practical problem is embedded in the above definition of the standard error of sample means.
To calculate the standard deviation of the means, we needed the standard deviation of the population
This is not usually something we know, so we need a fix
So, what can we use to estimate sigma, (![]() )?
)?
If we get something to estimate sigma with that we can actually measure, then we can use it to find the probability of a sample mean being close to the actual mean (
The most obvious estimate, and the one we will use is s, the standard deviation of the sample, which we will substitute into the formula for the standard deviation of the sample means
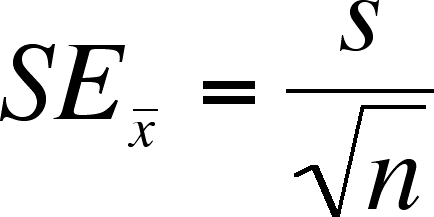
We call the standard error (SE) of the mean, not the standard deviation of the mean to distinguish between something calculated from the data and something calculated from a statistic (the sample means).
Difference between SE and SD
Standard deviation of the sample - refers to how the individual data points are distributed with respect to the mean, it is a measure of data dispersion.
Remember how it is computed (as the square root of the average [corrected for degrees of freedom] of the squared deviations of the data points from the mean [remember we square as a means of making all of the deviations positive])
Standard Error of the mean - refers to the probability that sample means, not individual data points, differ from the true population mean
The book states the same thing with different words. The book defines the SE as a measure of uncertainty due to sampling (random) error in how good a sample mean is as a measure of the true mean
A larger SE means there is more uncertainty in using the sample mean as an estimator of the true (population) mean
Remember that SE is related to s, but that it is always smaller than s
The divisor means that larger samples have a smaller SE, that is, that they are expected to be closer to the true mean than are sample means from smaller samples
Confidence Interval for the True Mean
A confidence interval is a range of values between which we believe the value of interest to lie
for us
The size of the range depends on two things
how sure we want to be
if we want to me more sure, then we must have a larger range
you can be somewhat sure that the true mean of the student age at TSU is between 20 and 30
you can be totally sure that the true mean of the student age at TSU is between 1 and 100
how much error variation there is the original population
If we knew
, the sample mean, given that the population is normally distributed
if you want to know how big a confidence interval you need to be 75% sure that the mean is in the value you have to find the z values that have 75% of the area under the normal curve between them (see below, to see that these values are about -1.03 and 1.03)
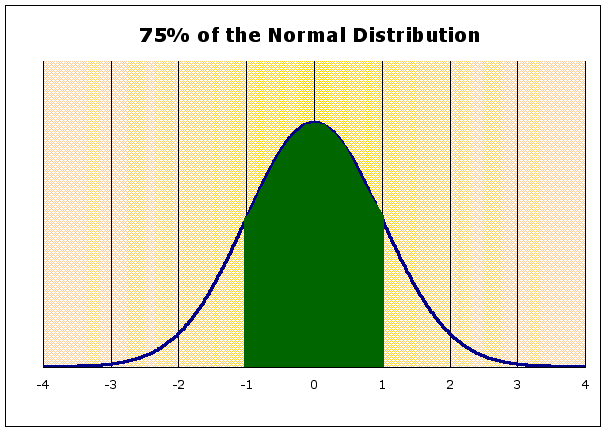
Then one would find X, the actual numbers, from the z values (remember how you calculate a z) as done below
The confidence interval when sigma is known:
Start with the proposition that the probability of Z being between -1.03 and 1.03 is 75%
Pr{ -1.03 < Z < 1.03} = 0.75
Substitute the formula for calculating Z based on
the sample mean (because it has ![]() and
and ![]() in it, and we want to know how one relates to the other)
in it, and we want to know how one relates to the other)
Pr{-1.03 <
< 1.03} = 0.75
Now do some simple algebra to find out where ![]() should lie
should lie
first, multiply by the denominator,
, to eliminate it from the middle term and then subtract
Pr{-1.03*
then subtract
Pr{
This last expression is a confidence interval.
It says that there is a 75% chance of the true mean being between the sample mean minus a term (based on a z value and the standard error of sample means) and the sample mean plus the same term.
We have done it, we have found out where the true mean is with a confidence level of 75% but there is a fly in the ointment, a bit of unfinished business
How can we find
We need an estimator of
There is a second problem, because the normal was
calculated with ![]() , not with SE or S
, not with SE or S
It turns out that the distribution of means follows a curve called Student's t, which is similar to the normal
it has a larger standard deviation term than does the normal
the difference between the t distribution and the normal is dependent on the sample size, such that smaller sample sized are less like the normal and larger are more similar
when sample size is infinitely large, the t and the normal distributions are identical
Calculating a confidence interval using the t-distribution
We can re-write the last equation for a confidence interval now
Pr{
so we need to calculate
We know how to do the sample mean and SE (from above), but what is t?
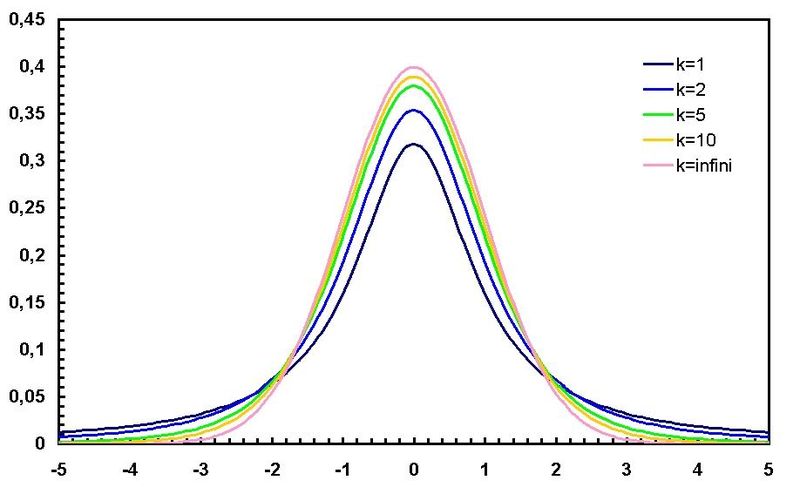
t refers to the student's-t distribution. It is a platykurtic (flattened) version of the normal distribution. There is more than one student's-t distribution. In fact, each sample size produces a unique t-distribution.
The shape of the distribution changes with n, the sample size. As n gets larger, the student's-t distribution becomes more and more similar to the normal (in fact, when n is infinitely large, they are the same.
In the figure below, the normal curve is in pink and is the curve with the highest peak that falls most steeply. Compare it with the student-t curve for a sample size of 1 (k is the degrees of freedom, which depends on the sample size - see below), which is black. The x-axis units are standard deviations and the y-axis is probability.
diagram from Wikipedia, Student's t Distribution entry, used here under GNU license
The peak of the student's-t distribution (black) is lower than the normal (pink) and the tails on either side for the student's t distribution are higher than for the normal distribution.
This means that, if I compare the areas under the curves that are less than -2 sd, then the area will be larger for the student-t distribution than for the normal.
Consider this: Which curve has more area within ± 1 sd of the mean (= 0 here). Since there is more area out in the tails for the student's-t distribution, then there must be less in the center, so it is the normal with more area (= greater probability) within a standard deviation of the mean.
This makes sense. A sample provides an estimate of the population. Estimates are not as accurate and so a curve based on estimates should have more "spread." As the size of the sample increases, the estimate gets better and better, which happens here because the student's-t distribution becomes more like the normal is n increases.
We can look the cumulative areas (probabilities) up in table 4, where the table body is the upper tail probability of the t-distribution and the rows an columns depend on the degrees of freedom and the critical value you want to use
Degrees of freedom are n-1 when only one parameter is being estimated (we are trying to estimate only
Critical value is the probability that the true mean will exceed the confidence interval
for the example above, the critical value was 25% (= 1 - 75%)
The table lists only the upper tail, and we are concerned about
if you want a critical value of 5%, you have to look up 0.025, not 0.05
This is an important question to ask when designing experiments.
If you will be using statistics to evaluate the results, then you don't want
to have too few data points to show a difference between experimental and controls
to have more data points than is necessary to show a difference between experimental and controls
The first instance can be a disaster
the second may be an inconvenience (doing more than needs to be done) or can mean that you get fewer experiments done because you are wasting effort
We will use the formula for the standard error of the mean to estimate n (see above for this formula)
You can't do this without some sort of guessing, but the guessing should make use of prior knowledge and your expertise.
Consider what you want the ± portion of the confidence interval to be (see example below)
You are measuring the concentration of a protein, and you think that the experimental cells might have as much as 20% more than the control cells. You will have to set up a series of flasks in which to rear cells and will measure the concentration of the protein in each flask. How many flasks do you need to set up?
You know that the control cells produce (from the literature or from previous work) about 25 picograms per microliter of protein with a standard deviation of 7 picograms per microliter.
You want to be 95% confident that your estimate of the concentrations will be within 5 picograms per microliter of the true mean
The 95% is an arbitrary choice, but it means that you have only a 1 in 20 chance of being wrong
You chose the 5 value because you expect the experimental to only be about 5 microliters above the controls (20%).
So you want the ± portion of the confidence interval to be no larger than 5
the ± portion is t0.025*SEx,
t has the subscript of 0.025 because you want to be 95% confident, so the critical value is 5% (1-0.95) and this is divided in half because the table has only the upper tail probability (=area under the curve), and you are concerned about both the upper and the lower tails (missing by being too large or too small an estimate)
from the table, t0.025=~2 (you don't know the degrees of freedom yet, but look at table 4 in the 0.025 column, and the values drop to about 2 very quickly, so 2 is a reasonable estimate)
So, we can find N now because we have all the information we need
5 = t0.025*SEx,
5 = 2 * S, and SEx = S/sqrt(n)
5 = 2 * 7 /sqrt(n)
sqrt(n) = 14/5 = 2.8
n = 2.8^2 = 7.84, so you need about 8 flasks to make an estimate accurate enough for your purposes
Validity of Confidence Intervals
First, the SEx must be a valid estimate
of ![]()
one observation (x) must not influence the size of other observations (x's)
consider the removal of a sample and then not replacing the sample
you are measuring an enzyme in the gut of rats
you have 5 rats and you take out the intestine and cut it into six pieces. Enzyme concentration is measured in each piece of gut
How many observations do you have? You have 30 (5 rats times 6 pieces per rat)
How many independent observations do you have? You have only 5 because the six from the same rat might all be influenced by the individual characteristics of the rat, and you are not interested in that rat per se, but in all rats
The confidence interval is valid if
this condition is strict if you want the CI to be exactly valid
this condition can be relaxed if:
the sample size is small and the population distribution is nearly normal
the sample size is large, in which case the population distribution is of no consequence (remember the central limit theorem)
Confidence Interval for a population proportion
The confidence interval for p will need an estimate of the standard error of p and an estimate of p, both of which are presented below and an assumption about t.
The estimate of p is not simply the frequency of an event over the size of the sample, but will include a correction factor of adding 2 to both the numerator and denominator.
If n is large, the correction factor does not change the outcome much
The SEp is based on the standard error done before (see book about using the normal to estimate the binomial)
The last portion is what to do about t, as we know that a binomial has only two outcomes (success and no success) and this can't be a normal distribution
Central limit theorem allows us to escape from this dilemma, so we will estimate the t0.05 value at 1.96 (from the normal)
Confidence Interval for p
p ± 1.96*SEp
Last updated September 7, 2006